この記事は Java Advent Calendar 2018 の 9 日目のエントリーです。
流行をとらえた話題が多いなか、10~15年前感のあるコンテンツです。化石です。 しかし化石とはいえ、よく使う技術ではあります。
ということで、何気なく使ってたけど改めて勉強し直しました。
検証バージョン
- java 1.8.0_181
- JDBCドライバ postgresql 42.2.5
- PostgreSQL 10.5 自前ビルド
検証環境
Java動作環境
- Windows 10 Pro ver.1803
- CPU 4コア(Hyper-Vと共用)
- RAM 16GB(うち、Hyper-Vへ8GB割り当て)
- Intel Core i5-4690 CPU 3.50GHz
- SSD
PostgreSQL動作環境
- Hyper-V 仮想インスタンス
- CentOS Linux release 7.1.1503 (Core)
- CPU 4コア(ホストと共用)
- RAM 8GB
JDBCとは
Javaからデータベースにアクセスするための標準API。
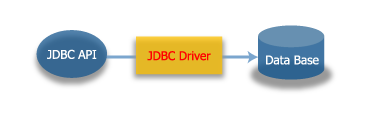 引用元
引用元 ドライバには様々なタイプが存在するが、今回は一番メジャーなタイプ4(全てJavaで実装されているドライバ)の話に絞る。
 引用元
引用元 データベースアクセスの流れ
大まかな流れは以下のようになる。
- ConnectionクラスでDBとの接続を確立する
- Statementクラスで実行したいSQLを定義して実行する
- ResultSetクラスでSQLの実行結果にアクセスする

コードは以下のようになる。(close()処理をさぼってるので注意)
public static void main(String[] args) throws SQLException {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/sampledb", "kimura", "test");
PreparedStatement pstmt = conn.prepareStatement("SELECT name,price FROM product");
pstmt.setFetchSize(2);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
System.out.println(rs.getString(1));
System.out.println(rs.getInt(2));
}
}
fetchSize
SQLの実行結果を一括でJava側に取得すると、全データがメモリ上に確保されることになる。過度なインスタンス生成はOutOfMemoryErrorにつながるため、データを分割して取ってくる仕組みがある。1回に取ってくるデータサイズがfetchSize。 処理速度とメモリ利用量のトレードオフを考慮して決めることになる。
検証する
30万程度のレコードをfetchSize=0 と fetchSize=1000で取得してみる。
SELECT count(*) FROM sample;
count
---------
3294112
(1 row)
PostgreSQL JDBC Driver の場合はfetchSizeを有効にするには以下の条件がある。 conn.setAutoCommit(false)を忘れずに実行する。
- The connection to the server must be using the V3 protocol. This is the default for (and is only supported by) server versions 7.4 and later.
- The Connection must not be in autocommit mode. The backend closes cursors at the end of transactions, so in autocommit mode the backend will have closed the cursor before anything can be fetched from it. *The Statement must be created with a ResultSet type of ResultSet.TYPE_FORWARD_ONLY. This is the default, so no code will need to be rewritten to take advantage of this, but it also means that you cannot scroll backwards or otherwise jump around in the ResultSet.
- The query given must be a single statement, not multiple statements strung together with semicolons.
Chapter 5. Issuing a Query and Processing the Result
public static void main(String[] args) throws SQLException, InterruptedException {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/postgres", "kimura", "test");
conn.setAutoCommit(false);
PreparedStatement pstmt = conn.prepareStatement("SELECT * FROM sample");
// 0と1000で試行する
pstmt.setFetchSize(0);
// この間にjconsoleをつなぐ
TimeUnit.SECONDS.sleep(15);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
System.out.println(rs.getString(1));
}
}
fetchSize=0 だと、メモリ利用量が多いが、実行時間は短い。

fetchSize=1000 だと、メモリ利用量が少ないが、実行時間は長い。

SPI
ConnectionやStatementやResultSetはすべてインタフェースである。
なぜインタフェースを通してプログラミングするだけでいいのか。実装クラスをnewする必要はないのか。これは、SPIという仕組みを利用している。
参考 Java Service Provider Interface
これによって、MyBatisなどの3thパーティのライブラリがJDBC APIを利用してコーディングしておけば、ライブラリの利用者側で好きなJDBC実装と組み合わせて使える。
PreparedStatement
ユーザ文字列をもとにSQLを組み立てるときに、ただの文字列として処理するとSQLインジェクションという脆弱性を生む可能性がある。PreparedStatementを使うと、この問題を防ぐことができる。
参考 Wikipedia SQLインジェクション
訴訟問題に発展する可能性もあるので、しっかりと対策したい。
参考 SQLインジェクション対策もれの責任を開発会社に問う判決
検証する
まず、SQLインジェクションの脆弱性がある残念なコードを作る。
public static void main(String[] args) throws Exception {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/sampledb", "kimura", "test");
Statement pstmt = conn.createStatement();
String userInput = "alice";
ResultSet rs = pstmt.executeQuery("SELECT name, password FROM users WHERE name = '" + userInput + "'");
while (rs.next()) {
System.out.println("name: " + rs.getString("name") +
", password: " + rs.getString("password"));
}
実行結果は以下のとおり。String userInput = "alice"に従った内容だけが取得できるので、特に問題ないように見える。
name: alice, password: secret1
次に、ユーザからの入力部分を String userInput = "alice' OR '1' = '1"; に変えて実行してみる。すると、他のユーザの情報にもアクセスできている。
name: bob, password: secret2
name: alice, password: secret1
ここの問題点は、意図せずにSQLの構造を変化させられていること。
こんなときに、PreparedStatementを使う。
public static void main(String[] args) throws Exception {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/sampledb?loggerLevel=DEBUG", "kimura", "test");
PreparedStatement pstmt =
conn.prepareStatement("SELECT name, password FROM users WHERE name = ?");
String userInput = "alice' OR '1' = '1";
pstmt.setString(1, userInput);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
System.out.println("name: " + rs.getString("name") +
", password: " + rs.getString("password"));
}
}
実行結果は以下の通り。先ほどのように、別のユーザ情報にアクセスできない。
PreparedStatementを利用すると、バインド変数部分が一つの文字列として解釈される。そのため、nameがalice' OR '1' = '1のものを探すことになる。意図せずにSQLの構造を変更させられることがないので、SQLインジェクション対策になる。
SQLException
DBまわりのエラーはSQLExceptionという型でスローされる。 getMessage()でエラー文言が、getSQLState()でエラーコードが取得できる。
参考 SQLException Javadoc
参考 The Java? Tutorials Handling SQLExceptions
PostgreSQLであれば、SQLStateは以下に詳細に定義されている。
PostgreSQL 10.5 付録A PostgreSQLエラーコード
またJDBC4からSQLExceptionに階層が定義されている。例えば、シンタックスエラーを表すSQLSyntaxErrorExceptionといった具合に。しかし、PostgreSQL JDBC Driverでは対応していない様子。
Github Issue 『Support for JDBC 4.0 exception hierarchy』
PSQLExceptionさえあればいいんや!…というのは冗談としても、実際にWEBアプリケーションを組む場合はフレームワークが独自の階層を持った例外クラスに変換してくれることが多い。なので、実害はないように思う。
例えばSpring Frameworkであれば、2.1. Consistent Exception Hierarchyに記載されているような例外の型階層に変換してくれる。
検証する
構文として問題のあるSQLを実行し、SQLExceptionの中身を表示する。
public static void main(String[] args) throws Exception {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/sampledb", "kimura", "test");
conn.setAutoCommit(false);
try {
// FROM のtypo
PreparedStatement pstmt = conn.prepareStatement("SELECT * FORM sample");
pstmt.executeQuery();
} catch (SQLException e) {
System.out.println(e.getErrorCode());
System.out.println(e.getSQLState());
System.out.println(e.getMessage());
}
}
実行結果は以下の通り。
0 // PostgreSQL JDBC Driverの場合は常に0
42601
ERROR: syntax error at or near "FORM"
位置: 10
ISOLATION_LEVEL
Connection#setTransactionIsolationメソッドでトランザクションの隔離性を設定できる。AutoCommitがtrueになっているとSQL実行ごとに自動でトランザクションがコミットされるため、Connection#setAutoCommit(false)と組み合わせることが多い。
ISOLATION_LEVELの詳細は、データベースの知識なので割愛する。ここらへんは以前に調べた。
PostgreSQL Isolation について - SIerだけど技術やりたいブログwww.kimullaa.com
JDBCコネクションプール
先述したConnectionをSQL実行の度にオープン/クローズすると、接続コスト(TCPコネクション確立~DBの認証)がその都度かかる。そのため、コネクションを使いまわすのがJavaの世界では一般的であり、この仕組みをコネクションプールと呼ぶ。
 引用元
引用元 コネクションプールの実装によるが、以下のパラメータはたいてい存在する。
- コネクションプール関連
- コネクションのバリデーション関連
- JDBC Driverのパラメータ操作関連
特に、コネクションプールの最大数を超えた要求が来た場合、要求スレッドはコネクションが返却されるのを待つことになる。最悪はタイムアウトして例外が発生することになるので、頻繁にタイムアウトが発生しないように注意する。
コネクションプールのメリット・デメリットは以下が詳しい。また、コネクションプール以外のデータベース接続アーキテクチャも記載されているので、ぜひとも一読するべき。
参考 Webシステムにおけるデータベース接続アーキテクチャ概論
AP視点のメリット
DriverManager#getConnectionしたときのパケットをWireSharkでキャプチャすると、クライアント~サーバ間で複数回の通信が行われていることがわかる。

コネクションをプールすることで、上記のやり取りを省略できる。
検証する
以下の3つで、どれくらい接続コストが違うのかを確かめる。
- 単純にコネクションを使いまわした場合
- コネクションプールライブラリを使った場合
- 都度接続した場合
なお、PostgreSQLは同一ホストの仮想環境に立っているので、ネットワーク的な遅延が低い状況である。
単純にコネクションを使いまわした場合
private static final int LOOP_COUNT = 10000;
public static void main(String[] args) throws SQLException, InterruptedException {
long start = System.currentTimeMillis();
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/postgres", "kimura", "test");
for (int i = 0; i < LOOP_COUNT; i++) {
PreparedStatement pstmt = conn.prepareStatement("SELECT 1");
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
}
rs.close();
pstmt.close();
}
conn.close();
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start));
}
コネクションプールライブラリを使った場合
private static final int LOOP_COUNT = 10000;
public static void main(String[] args) throws Exception {
HikariConfig config = new HikariConfig();
config.setUsername("kimura");
config.setPassword("secret");
config.setJdbcUrl("jdbc:postgresql://192.168.11.116:5432/sampledb");
config.setMaximumPoolSize(2);
long start = System.currentTimeMillis();
HikariDataSource ds = new HikariDataSource(config);
for (int i = 0; i < LOOP_COUNT; i++) {
Connection conn = ds.getConnection();
PreparedStatement pstmt = conn.prepareStatement("SELECT 1");
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
}
rs.close();
pstmt.close();
conn.close();
}
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start));
}
都度接続した場合
private static final int LOOP_COUNT = 10000;
public static void main(String[] args) throws SQLException, InterruptedException {
long start = System.currentTimeMillis();
for (int i = 0; i < LOOP_COUNT; i++) {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/postgres", "kimura", "test");
PreparedStatement pstmt = conn.prepareStatement("SELECT 1");
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
}
rs.close();
pstmt.close();
conn.close();
}
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start));
}
実行結果は以下の通り。
| コネクション使いまわし | コネクションプールライブラリ(HikariCP) | 都度接続 | |
|---|---|---|---|
| 1回目 | 2124 | 2522 | 42304 |
| 2回目 | 2363 | 2538 | 42890 |
| 3回目 | 2352 | 2593 | 41420 |
| 4回目 | 2275 | 2594 | 43021 |
| 5回目 | 2291 | 2280 | 43948 |
| 平均(ms) | 2281 | 2505.4 | 42716.6 |
接続コスト(TCPコネクション確立~DBの認証)はそれなりにかかる、ということがわかった。
JDBCコネクションプール(DB視点)
PostgreSQLはコネクションごとにpostgresプロセスをforkする。
PostgreSQL 10.5 第50章 PostgreSQL内部の概要 The Internals of PostgreSQL Process and Memory Architecture
引用元 The Internals of PostgreSQL Process and Memory Architecture

そのため、同時接続数分だけプロセスを生成することになる。例えば、コネクションプール=3のときのPostgreSQLのプロセスは以下のようになる。
]$ ps -ef | grep postgres
kimura 1721 61604 0 13:21 ? 00:00:00 postgres: kimura sampledb 192.168.11.104(61246) idle
kimura 1730 61604 0 13:22 ? 00:00:00 postgres: kimura sampledb 192.168.11.104(61251) idle
kimura 1734 61604 0 13:22 ? 00:00:00 postgres: kimura sampledb 192.168.11.104(61253) idle
...
以下の理由から、コネクションプールを利用すると安定運用しやすい。
- 都度プロセスを生成するとコストが高い
- 同時接続数が決まるので、リソース使用量を見積もりやすい
検証する
都度プロセスを生成するのは、どのくらいコストが高いのかを確かめる。以下のコードを10秒間実行し、sarコマンドでCPU使用状況の平均を取る。
PostgreSQLの同時接続数は10と仮定する。
コネクション使いまわし(同時接続10)
public static void main(String[] args) throws Exception {
ExecutorService service = Executors.newFixedThreadPool(10);
for (int j = 0; j < 10; j++) {
service.submit(() -> {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/postgres", "kimura", "test");;
while (true) {
try {
PreparedStatement pstmt = conn.prepareStatement("SELECT 1");
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
}
rs.close();
pstmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
});
}
}
都度接続(同時接続10)
public static void main(String[] args) throws Exception {
ExecutorService service = Executors.newFixedThreadPool(10);
for (int j = 0; j < 10; j++) {
service.submit(() -> {
while (true) {
try {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/postgres", "kimura", "test");
PreparedStatement pstmt = conn.prepareStatement("SELECT 1");
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
}
rs.close();
pstmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
});
}
}
1つめがコネクション使いまわし、2つめが都度接続。
CPU %user %nice %system %iowait %steal %idle
平均値: all 4.09 0.00 33.13 0.00 0.00 62.78
平均値: all 14.24 0.00 61.06 0.03 0.00 24.68
(かなりアバウトかつDB負荷が高い条件ではあるけど)コネクションを使いまわしたほうが、DBとしても負荷が低いことがわかった。
workerプロセスごとにメモリをどれくらい使うのか
コネクションプールした状態だと、どの位メモリを消費するかを確認する。都度接続のコードでConnection#close()せずに、10000本コネクションを張る。
テスト実行の前にキャッシュを捨てる。
]# echo 3 > /proc/sys/vm/drop_caches
サーバ全体のメモリ状況は、検証前後で以下のようになった。
]$ free
total used free shared buff/cache available
Mem: 10391784 5721584 4118352 370328 551848 4194024
Swap: 2097148 0 2097148
// 10000本コネクションを張る
]$ free
total used free shared buff/cache available
Mem: 10391784 6269028 3277516 372400 845240 3357384
Swap: 2097148 0 2097148
次に、workerプロセスに絞ったメモリ利用量は以下のようになった。
]$ ps aux | grep "postgres: kimura postgres" | grep -v grep | awk '{print $2}' | xargs -i% cat /proc/%/smaps | awk '/^Pss/{sum += $2}END{print sum}'
2367442 (kb)
PSSは物理メモリの使用量(共有メモリ分は、プロセス数で割った値を使う)のこと。
参考 プロセス毎のメモリ消費量を調べたい時に使えるコマンド
PostgreSQLは共有メモリにディスクから取得したデータをキャッシュするので、RSSで見るとメモリ利用量を過大評価したことになるため。
参考 The Internals of PostgreSQL Buffer Manager
実行中のworkerの場合はwork_memやtemp_buffersなどが上乗せされるので、最終的にはメモリ利用量はもっと増えるはず。
PreparedStatementのキャッシュ
DBCP2などのコネクションプールライブラリは、PrepatedStatementインスタンスを破棄せずに内部でキャッシュする。これによって、インスタンス生成コストが抑えられる。
ただし最近流行りのHikariCPでは、この機能を提供しておらず、次に示すサーバサイドステートメントキャッシュのみを提供している。
Many connection pools, including Apache DBCP, Vibur, c3p0 and others offer PreparedStatement caching. HikariCP does not. HikariCP README
検証する
DBCP2を利用して、PreparedStatementがキャッシュされるのを確認する。
Apache Common DBCP2 BasicDataSource Configuration Parameters
PreparedStatementがキャッシュされるのを確認する
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.setProperty("username", "kimura");
props.setProperty("password", "secret");
props.setProperty("url", "jdbc:postgresql://192.168.11.116:5432/sampledb");
props.setProperty("driverClassName", "org.postgresql.Driver");
props.setProperty("poolPreparedStatements", "true");
DataSource ds = BasicDataSourceFactory.createDataSource(props);
while (true) {
Connection conn = ds.getConnection();
PreparedStatement pstmt = conn.prepareStatement("SELECT 1");
Object pgstmt = pstmt.unwrap(DelegatingStatement.class)
.getDelegate()
.unwrap(DelegatingPreparedStatement.class).getDelegate()
.unwrap(PoolablePreparedStatement.class).getDelegate();
System.out.println(pgstmt.getClass() + " " + pgstmt.hashCode());
pstmt.close();
conn.close();
}
}
実行結果は以下の通り。
class org.postgresql.jdbc.PgPreparedStatement 627150481
class org.postgresql.jdbc.PgPreparedStatement 627150481
class org.postgresql.jdbc.PgPreparedStatement 627150481
class org.postgresql.jdbc.PgPreparedStatement 627150481
class org.postgresql.jdbc.PgPreparedStatement 627150481
class org.postgresql.jdbc.PgPreparedStatement 627150481
PreparedStatementインスタンスがキャッシュされていることがわかる。
次に、どれくらい性能が上がるかを調べる。
private static final int LOOP_COUNT = 10000;
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.setProperty("username", "kimura");
props.setProperty("password", "secret");
props.setProperty("url", "jdbc:postgresql://192.168.11.116:5432/sampledb");
props.setProperty("driverClassName", "org.postgresql.Driver");
// trueとfalseで比較する
props.setProperty("poolPreparedStatements", "false");
long start = System.currentTimeMillis();
DataSource ds = BasicDataSourceFactory.createDataSource(props);
for (int i = 0; i < LOOP_COUNT; i++) {
Connection conn = ds.getConnection();
PreparedStatement pstmt = conn.prepareStatement("SELECT 1");
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
}
rs.close();
pstmt.close();
conn.close();
}
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start));
}
結果は以下の通り。
| キャッシュあり | キャッシュなし | |
|---|---|---|
| 1回目 | 3689 | 4013 |
| 2回目 | 3485 | 3571 |
| 3回目 | 3741 | 3805 |
| 4回目 | 3957 | 4026 |
| 5回目 | 3674 | 3894 |
| 平均(ms) | 3709.2 | 3861.8 |
PreparedStatementのキャッシュだけではあんまり差がでない。DBCP2的にも poolPreparedStatements はデフォルトでfalse。まあ、そういうことなんだろう。
サーバサイドステートメントキャッシュ
JDBCドライバがサーバ側のプリペアド機能を利用して実現するキャッシュ。
PostgreSQLでは、同一コネクションで同じSQLが複数(デフォルトでは5回)発行されると、サーバサイドステートメントキャッシュが有効になる。
バックエンドは複数のプリペアド文とポータルの経過を追うことができます (しかし、1つのセッション内でのみ存在可能です。複数のセッションで共有することはできません)。
PostgreSQL 10.5 第52章 フロントエンド/バックエンドプロトコル
プリペアド文が利用されるとDB側の構文解析や実行計画といったフェーズがスキップできるため、DB側の処理が削減される。
 引用元
引用元 また、JDBCドライバとしても、通信時にヘッダー情報を要求しなくなる、といった通信プロトコルレベルの最適化を実施する。
しかし、プリペアド文を利用すると、コネクションごとに構文解析したクエリやカーソルが保持される。メモリ消費を制限するための上限を設定するパラメータとして、preparedStatementCacheQueries(デフォルト 256) や preparedStatementCacheSizeMiB(デフォルト 5) がある。
参考 PostgreSQL JDBC Driver hapter 9. PostgreSQL? Extensions to the JDBC API
検証する
サーバサイドステートメントキャッシュの性能差を比較する。 PgConnection#setPrepareThresholdでサーバサイドステートメントキャッシュのしきい値を設定する。
private static final int LOOP_COUNT = 10000;
public static void main(String[] args) throws SQLException, InterruptedException {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/postgres", "kimura", "test");
PGConnection pgconn = conn.unwrap(PGConnection.class);
// 有効のときは 1 を設定。無効のときは LOOP_COUNT + 1 を設定
pgconn.setPrepareThreshold(LOOP_COUNT + 1);
conn.setAutoCommit(false);
PreparedStatement pstmt = conn.prepareStatement("SELECT * from sample WHERE id = ?");
long start = System.currentTimeMillis();
for (int i = 0; i < LOOP_COUNT; i++) {
pstmt.setInt(1, i);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
}
}
long end = System.currentTimeMillis();
System.out.println("time: " + (end - start));
}
実行結果は以下の通り。
| prepareThresholdが有効 | prepareThresholdが無効 | |
|---|---|---|
| 1回目 | 2165 | 3207 |
| 2回目 | 2222 | 3177 |
| 3回目 | 2146 | 3170 |
| 4回目 | 2447 | 3230 |
| 5回目 | 1944 | 3076 |
| 平均(ms) | 2184.8 | 3172 |
PrepareThresholdが効いているほうが、けっこう早く終わることがわかった。
リクエストの最適化
通常のリクエスト。だいたい5ステップある。
...
PostgreSQL
Type: Parse // 構文解析
Length: 54
Statement:
Query: SELECT id, price FROM sample WHERE id = $1
Parameters: 1
Type OID: 23
PostgreSQL
Type: Bind // $1の変数の値をセット
Length: 22
Portal:
Statement:
Parameter formats: 1
Format: Binary (1)
Parameter values: 1
Column length: 4
Data: 00000002
Result formats: 0
PostgreSQL
Type: Describe // レスポンスにヘッダー情報付与
Length: 6
Portal:
PostgreSQL
Type: Execute // SQL実行
Length: 9
Portal:
Returns: all rows
PostgreSQL
Type: Sync // お決まりのやつらしい
Length: 4
ステートメントキャッシュ開始時点のリクエスト。
- ParseにStatementが指定されている
...
PostgreSQL
Type: Parse // プリペアド文の要求
Length: 57
Statement: S_1
Query: SELECT id, price FROM sample WHERE id = $1
Parameters: 1
Type OID: 23
PostgreSQL
Type: Bind // $1の変数の値をセット
Length: 25
Portal:
Statement: S_1
Parameter formats: 1
Format: Binary (1)
Parameter values: 1
Column length: 4
Data: 00000002
Result formats: 0
PostgreSQL
Type: Describe // レスポンスにヘッダー情報付与
Length: 6
Portal:
PostgreSQL
Type: Execute // SQL実行
Length: 9
Portal:
Returns: all rows
PostgreSQL
Type: Sync // お決まりのやつらしい
Length: 4
ステートメントキャッシュが有効になったあとのリクエスト。
- Parseが無くなっている
- Describeがなくなっている
...
PostgreSQL
Type: Bind
Length: 29
Portal:
Statement: S_1
Parameter formats: 1
Format: Binary (1)
Parameter values: 1
Column length: 4
Data: 00000002
Result formats: 2
Format: Binary (1)
Format: Binary (1)
PostgreSQL
Type: Execute
Length: 9
Portal:
Returns: all rows
PostgreSQL
Type: Sync
Length: 4
レスポンスの最適化
通常のレスポンス。
...
PostgreSQL
Type: Parse completion //構文解析完了
Length: 4
PostgreSQL
Type: Bind completion // $1の変数の値をセットが完了
Length: 4
PostgreSQL
Type: Row description // Describe要求に対応
Length: 51
Field count: 2
Column name: id
Table OID: 24576
Column index: 1
Type OID: 23
Column length: 4
Type modifier: -1
Format: Text (0)
Column name: price
Table OID: 24576
Column index: 2
Type OID: 23
Column length: 4
Type modifier: -1
Format: Text (0)
PostgreSQL
Type: Data row // データ行
Length: 18
Field count: 2
Column length: 1
Data: 32
Column length: 3
Data: 323030
PostgreSQL
Type: Command completion //コマンド完了
Length: 13
Tag: SELECT 1
PostgreSQL
Type: Ready for query // 次の要求待ち
Length: 5
Status: Idle (73)
ステートメントキャッシュが有効になった状態のレスポンス。
- テーブルヘッダ情報がない
- Data row にも型情報がない
...
PostgreSQL
Type: Bind completion // $1の変数の値をセットが完了
Length: 4
PostgreSQL
Type: Data row // データ行
Length: 22
Field count: 2
Column length: 4
Data: 00000002
Column length: 4
Data: 000000c8
PostgreSQL
Type: Command completion //コマンド完了
Length: 13
Tag: SELECT 1
PostgreSQL
Type: Ready for query // 次の要求待ち
Length: 5
Status: Idle (73)
異なるPreparedStatementインスタンスでもキャッシュが効くか
同一コネクションから生成されたPreparedStatementインスタンスであれば、各インスタンスをまたいでキャッシュが効くことを確認する。
public static void main(String[] args) throws Exception {
Connection conn = DriverManager.getConnection("jdbc:postgresql://192.168.11.116:5432/sampledb", "kimura", "test");
PGConnection pgconn = conn.unwrap(PGConnection.class);
pgconn.setPrepareThreshold(2);
for (int i = 0; i < 2; i++) {
PreparedStatement pstmt = conn.prepareStatement("SELECT 1");
PGStatement pgStatement = pstmt.unwrap(PGStatement.class);
System.out.println(pgStatement.isUseServerPrepare());
pstmt.executeQuery();
pstmt.close();
}
}
実行結果は以下の通り。
false
true
同一Connecionであれば、PreparedStatementが違ってもキャッシュされることがわかった。 ソースコードでいうと、以下のあたりが該当箇所だった。 PgPreparedStatement#executeInternal QueryExecutorImpl#sendParse
最後に
JDBCドライバは断片的な知識をもとにググりながら使うことが多かったので、全体的に学び直すことでいい勉強になった。