Linux カーネルのメモリ管理方法について、勉強したことをまとめる。プロセス編。
カーネル編はこちら。
Linux メモリ管理 徹底入門(カーネル編) - SIerだけど技術やりたいブログwww.kimullaa.com
OS は CentOS7.6、カーネルは次のバージョンを利用する。
]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
]# uname -a
Linux localhost.localdomain 3.10.0-957.21.3.el7.x86_64 #1 SMP Tue Jun 18 16:35:19 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
メモリ管理の特徴
メモリの使い方を簡素化すると、次の図のようになる。 どのような特徴があるかをまとめる。

連続したメモリ領域
プログラムは実メモリ上の配置を気にせずに(物理メモリが連続していなくて良い)、仮想アドレス上でフラットなメモリ領域を確保しているという前提で動ける。
これにより、コンパイルしたプログラムを何度でも実行できる。(もし実行ごとにメモリの開始位置が変わると、配置される場所ごとに機械語の修正が必要になる)
プロセスごとに独立したアドレス空間
プロセスごとに独立したアドレス空間を持つことができる。プロセスは仮想アドレスを通してのみメモリにアクセスするため、自プロセスが使ってる実メモリ領域を他プロセスが破壊できない。
実行例
引数を変数に代入してから画面に出力するプログラムを用意する。
#include <stdio.h>
int x;
int main(int argc, char *argv[]) {
x = atoi(argv[1]);
sleep(5);
printf("x = %d\n", x);
return 0;
}
コンパイル->逆アセンブルすると、変数 xが固定アドレス番地に存在することがわかる。
]# gcc -g3 main.c
]# objdump -S -d a.out
...
00000000004005ad <main>:
#include <stdio.h>
int x;
int main(int argc, char *argv[]) {
4005ad: 55 push %rbp
4005ae: 48 89 e5 mov %rsp,%rbp
4005b1: 48 83 ec 10 sub $0x10,%rsp
4005b5: 89 7d fc mov %edi,-0x4(%rbp)
4005b8: 48 89 75 f0 mov %rsi,-0x10(%rbp)
x = atoi(argv[1]);
4005bc: 48 8b 45 f0 mov -0x10(%rbp),%rax
4005c0: 48 83 c0 08 add $0x8,%rax
4005c4: 48 8b 00 mov (%rax),%rax
4005c7: 48 89 c7 mov %rax,%rdi
4005ca: b8 00 00 00 00 mov $0x0,%eax
4005cf: e8 bc fe ff ff callq 400490 <atoi@plt>
<< アドレス番地が固定 >>
4005d4: 89 05 66 0a 20 00 mov %eax,0x200a66(%rip) # 601040 <__TMC_END__>
sleep(5);
4005da: bf 05 00 00 00 mov $0x5,%edi
4005df: b8 00 00 00 00 mov $0x0,%eax
4005e4: e8 b7 fe ff ff callq 4004a0 <sleep@plt>
...
実アドレスに直接マッピングされている場合、このプログラムを2回同時に実行すると、変数xの値を上書きしあうはず。が、仮想アドレスのおかげで独立してメモリを利用できる。
]# ./a.out 1 &
[1] 75298
]# ./a.out 2 &
[2] 75443
]# x = 1
x = 2
[1]- 終了 ./a.out 1
[2]+ 終了 ./a.out 2
メモリの効率的な割り当て
メモリは4つの状態のいずれかになる。
- アロケートなし
- アロケート済み、マッピングなし
- アロケート済み、実メモリにマッピング
- アロケート済み、スワップにマッピング

デマンドページング
仮想メモリを割り当てたとして、プロセスが全てのメモリをすぐに利用するとは限らない。そのため、Linuxカーネルでは、必要になったときに実メモリを割り当てる。

具体的には、 MMU が仮想ページと実ページを変換したときに未割り当てだった場合、CPU がページフォールト例外を発生させる。これをきっかけにLinuxカーネルが実メモリを割り当てることで、実メモリよりも大きいメモリを仮想的に扱うことができる(オーバーコミット)。
※ 一部カーネル空間でもデマンドページングが行われる(vmalloc など)が、大部分はプロセス空間の話なのでここに記載する。
スワップ
活用されないプロセスのために物理メモリを確保するのは無駄。使わないメモリは一度ディスクに追い出しておき(スワップアウト)、必要なときにメモリに引き上げる(スワップイン)。

適度にスワップが発生している状況は異常ではないが、常にスワップが発生し続けているとスワップ処理ばかりが実行され、本来の処理がほとんど進まない状態になる。これはスラッシングと呼ばれる。たいていはメモリ増設が必要な状況。
具体的にスワップ設定にどのような値を設定すればいいかは、以下が参考になる。
参考 Linuxのスワップ処理を最適化するためのヒント (1/4)
2種類のメモリ種別
メモリには大きく分けて File Backed と Anonymous がある。スワップするのは Anonymous だけ。
File Backed
- 実体がファイルシステム上に存在するもの
- 主に mmap で確保されるメモリやファイルキャッシュ
- メモリ上のデータが更新されるとファイルと乖離が出る(=Dirty)
- メモリを解放するときは、 Dirty なものをディスクに書き出す必要がある
Anonymous
- 実体がファイルシステム上に存在しないもの
- 主にデータ領域やヒープ領域
- スワップ対象
- スワップアウトは裏で非同期に実行されるため性能問題になりづらい
- スワップインはページフォールトが発生してから同期的に実行されるため性能問題になりやすい
これらは /proc/meminfo にも表現されている。
]$ cat /proc/meminfo
...
Active(anon): 3191984 kB
Inactive(anon): 471200 kB
Active(file): 601916 kB
Inactive(file): 159540 kB
...
SwapTotal: 2097148 kB
SwapFree: 2097148 kB
...
実行例(オーバーコミット)
まずはオーバーコミットが有効になっているかを確認する。
]# sysctl vm.overcommit_memory
vm.overcommit_memory = 0
0 は明らかに足りない量のメモリを割り当てることは防ぐが、トータルで実メモリよりも仮想メモリを割り当てることはできるモード。詳細は、次のリンクを参考にする。
参考 Kernel Documentation overcommit-accounting
実メモリは 13GBある。
]# cat /proc/meminfo | grep MemTotal
MemTotal: 13831304 kB // トータル13GB
合計 30 GB 確保するプログラムを作成し、実行する。
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
// 10GB 割り当てる
if (malloc(10000000000) == NULL) {
perror("malloc failed");
return 1;
}
if (malloc(10000000000) == NULL) {
perror("malloc failed");
return 1;
}
if (malloc(10000000000) == NULL) {
perror("malloc failed");
return 1;
}
sleep(3);
return 0;
}
]# gcc -g3 main.c
// 物理アドレスを超えたサイズを確保することになるが、エラーにならない
]# ./a.out &
メモリを 30GB 確保したが、メモリ利用量は上がらないことがわかる。
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
2 0 0 6311636 3480 5045504 0 0 0 0 1057 3397 7 30 63 0 0
<< start >>
2 0 0 6354924 3480 5045524 0 0 0 0 1174 3745 8 30 62 0 0
2 0 0 6323816 3480 5045480 0 0 0 0 1087 3494 8 30 62 0 0
2 0 0 6185676 3480 5045464 0 0 0 0 1149 3766 7 31 63 0 0
<< end >>
2 0 0 6290936 3480 5045460 0 0 0 0 1093 3443 7 30 63 0 0
実行例(スワップ)
スワップ領域は パーティション/ファイル 単位で作成できる。今回はデフォルトで作成済みのスワップ領域を使うため、スワップ作成の詳細は割愛する。
参考 linux スワップ(swap)領域の作成
スワップ領域は swapon で表示できる。
]# swapon -s
Filename Type Size Used Priority
/dev/dm-1 partition 2097148 0 -2
メモリを 1GB 確保するプログラムをいくつか実行し、スワップが利用されるところを確認する。
// 1GBメモリを割り当てる
// スワップが起きるまでコマンドを何回か実行する
]# stress -m 1 --vm-bytes 1G --vm-hang 0 &
vmstat でメモリ利用量を見ると、徐々に実メモリの空き(free)が下がっていくことがわかる。また、実メモリの空きが足りなくなったところで、スワップアウトが発生していることがわかる。
]# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 2504996 3076 194540 0 0 0 0 46 212 0 3 97 0 0
0 0 0 3664524 3076 194540 0 0 0 0 53 250 1 6 94 0 0
0 0 0 2613848 3076 194540 0 0 0 0 40 181 0 3 97 0 0
0 0 0 1562932 3076 194540 0 0 0 0 47 236 0 2 98 0 0
0 0 0 1562844 3076 194540 0 0 0 0 22 127 0 0 100 0 0
0 0 0 1340288 3076 194540 0 0 0 0 104 326 0 2 98 0 0
0 0 0 2029816 3076 194540 0 0 0 4 36 180 0 0 100 0 0
1 0 0 699540 3076 194572 0 0 0 0 58 236 1 3 96 0 0
<< スワップが発生する >>
0 7 101128 71956 0 117688 0 100560 16132 100560 658 1277 1 8 25 66 0
0 9 215560 69636 0 120712 32 657228 45640 657228 1110 1936 0 3 6 91 0
1 6 1208840 68724 0 112120 368 665956 20648 665956 5433 7850 0 6 6 88 0
<< memory free が上昇する >>
0 0 1581064 153128 0 122524 252 156848 1116 156848 769 594 0 3 62 35 0
0 0 1581064 152792 0 122516 160 0 236 0 36 211 0 0 100 0 0
0 0 1581064 152792 0 122516 0 0 0 0 22 130 0 0 100 0 0
興味深い点として、後半に一度下がった memory free が上昇している。これは、メモリに空きを作るために OOM Killer がプロセスを強制終了したため。
コンソールにも、プロセスが強制終了されたことを表すメッセージが表示された。
-lstress: FAIL: [22153] (415) <-- worker 22154 got signal 9
stress: WARN: [22153] (417) now reaping child worker processes
stress: FAIL: [22153] (451) failed run completed in 49s
同様の内容がdmesg にも表示される。
]# dmesg | grep 22154
[14025.712413] Out of memory: Kill process 22154 (stress) score 66 or sacrifice child
[14025.712415] Killed process 22154 (stress) total-vm:1055888kB, anon-rss:1048648kB, file-rss:0kB, shmem-rss:0kB
実メモリ空間の共有
条件を満たしたページは、実メモリを共有することができる。

メモリの利用量
メモリは部分的に共有されるため、メモリの利用量にはいくつかの用語がある。
参考 LINUX MEMORY EXPLAINED
参考 Is this explanation about VSS/RSS/PSS/USS accurate?
| 名前 | 意味 |
|---|---|
| vss(virtual set size) | 実ページを未割当の領域も含めた、仮想メモリの合計値。 |
| uss(unique set size) | 自身のプロセスでのみ使っている実メモリの値。exitしたら解放される。 |
| pss(proportional set size) | 共有する部分をプロセス数で等分した値 + uss |
| rss(resident set size) | 自身のプロセスが使っている実メモリの合計値 |

実行例(vssとrss)
次のサンプルを実行し、vss と rss の利用量を調べる。
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
// 5GB 割り当てる
if (malloc(5000000000) == NULL) {
perror("malloc failed");
return 1;
}
// 5GB 割り当てる
if (malloc(5000000000) == NULL) {
perror("malloc failed");
return 1;
}
sleep(100);
return 0;
}
vsz(vss) は仮想メモリのサイズなので、malloc で確保した 10GB 近くになる。 rss は実メモリのサイズなので、356KiB で済んでいる。
]# gcc main.c
]# ./a.out &
[2] 19912
]# ps -aux | grep [1]9912
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 19912 0.0 0.0 9769840 356 pts/0 S 16:56 0:00 ./a.out
実行例(pss)
pss は共有されたページサイズをプロセス数で分割するため、/proc/${pid}/smaps のRss を プロセス数 で割った数になる。
]# sleep 1000 &
[1] 21244
]# cat /proc/21244/smaps | head
00400000-00406000 r-xp 00000000 fd:00 134924350 /usr/bin/sleep
Size: 24 kB
Rss: 16 kB
Pss: 16 kB // 1プロセスなので Rss = Pss
...
]# sleep 1000 &
[2] 21253
]# cat /proc/21244/smaps | head
00400000-00406000 r-xp 00000000 fd:00 134924350 /usr/bin/sleep
Size: 24 kB
Rss: 16 kB
Pss: 8 kB // 2プロセスに増えたので Rss / 2
...
// プロセス全体の pss
]# cat /proc/21457/smaps | awk '/^Pss/{sum += $2}END{print sum}'
106 //kB
実行例(uss)
uss は Private_Clean と Private_Dirty の合計になる。
]# sleep 1000 &
[1] 21388
]# sleep 1000 &
[2] 21389
]# cat /proc/21389/smaps | head
00400000-00406000 r-xp 00000000 fd:00 134924350 /usr/bin/sleep
Size: 24 kB
Rss: 16 kB
Pss: 8 kB
Shared_Clean: 16 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB // このプロセスだけで使ってる領域がないため 0 kB
Private_Dirty: 0 kB //
...
// プロセス全体の uss
]# cat /proc/21389/smaps | awk '/^Shared/{sum += $2}END{print sum}'
528 //kB
ちなみに
デマンドページングや物理メモリの共有が全く行われない場合、どれだけ実メモリが必要になるか(プロセス全体のvssの合計)を調べてみた。愚直に実装すると 330 GB かかるメモリが、Linux の様々な工夫によって約 3.6 GB で動作している。ということで、Linux はとっても節約が上手だということがわかった。
]$ ps -eo vsz | awk '{sum}{sum+=$1} END{print sum}'
322933272 // ≒ 330GB
]$ free -hm
total used free shared buff/cache available
Mem: 13G 3.6G 8.5G 101M 1.1G 9.2G
Swap: 2.0G 0B 2.0G
メモリ空間
プロセスのためのメモリ空間。
実行可能プログラムは ELF(Executable and Linkable Format) 形式が一般的。 ELF 形式のファイルを作成したリンカとLinuxカーネルがメモリレイアウトを決める。
参考 ELF実行ファイルのメモリ配置はどのように決まるのか
メモリレイアウト
単純化すると、次の図のようになる。

実行中プロセスのメモリレイアウトの詳細は /proc/pid/maps で参照できる。
]# cat /proc/self/maps
00400000-0040b000 r-xp 00000000 fd:00 134924284 /usr/bin/cat
0060b000-0060c000 r--p 0000b000 fd:00 134924284 /usr/bin/cat
0060c000-0060d000 rw-p 0000c000 fd:00 134924284 /usr/bin/cat
0060d000-0062e000 rw-p 00000000 00:00 0 [heap]
7ffff14e4000-7ffff7a0e000 r--p 00000000 fd:00 67111375 /usr/lib/locale/locale-archive
7ffff7a0e000-7ffff7bd0000 r-xp 00000000 fd:00 201505758 /usr/lib64/libc-2.17.so
7ffff7bd0000-7ffff7dd0000 ---p 001c2000 fd:00 201505758 /usr/lib64/libc-2.17.so
7ffff7dd0000-7ffff7dd4000 r--p 001c2000 fd:00 201505758 /usr/lib64/libc-2.17.so
7ffff7dd4000-7ffff7dd6000 rw-p 001c6000 fd:00 201505758 /usr/lib64/libc-2.17.so
7ffff7dd6000-7ffff7ddb000 rw-p 00000000 00:00 0
7ffff7ddb000-7ffff7dfd000 r-xp 00000000 fd:00 201327254 /usr/lib64/ld-2.17.so
7ffff7fdf000-7ffff7fe2000 rw-p 00000000 00:00 0
7ffff7ff9000-7ffff7ffa000 rw-p 00000000 00:00 0
7ffff7ffa000-7ffff7ffc000 r-xp 00000000 00:00 0 [vdso]
7ffff7ffc000-7ffff7ffd000 r--p 00021000 fd:00 201327254 /usr/lib64/ld-2.17.so
7ffff7ffd000-7ffff7ffe000 rw-p 00022000 fd:00 201327254 /usr/lib64/ld-2.17.so
7ffff7ffe000-7ffff7fff000 rw-p 00000000 00:00 0
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
各行はメモリリージョンを表している。 メモリリージョンは、メモリを 実行/参照/共有 といった用途ごとに分けたブロック。
/proc/[pid]/maps A file containing the currently mapped memory regions and their access permissions. See mmap(2) for some further information about memory mappings. 参考 man proc
ASLR(Address Space Location Randomization)
同じプログラムを実行したとしても、メモリ位置は実行ごとに異なる。 これはセキュリティ対策のひとつで、バッファオーバフローが起きたときに任意のコードを実行しずらくするために、メモリ位置をランダム化しているため。
参考 ASLRとKASLRの概要
]# cat /proc/self/maps
...
010dd000-010fe000 rw-p 00000000 00:00 0 [heap]
7f18c86e2000-7f18cec0c000 r--p 00000000 fd:00 67111375 /usr/lib/locale/locale-archive
7f18cec0c000-7f18cedce000 r-xp 00000000 fd:00 201505758 /usr/lib64/libc-2.17.so
7f18cedce000-7f18cefce000 ---p 001c2000 fd:00 201505758 /usr/lib64/libc-2.17.so
7f18cefce000-7f18cefd2000 r--p 001c2000 fd:00 201505758 /usr/lib64/libc-2.17.so
7f18cefd2000-7f18cefd4000 rw-p 001c6000 fd:00 201505758 /usr/lib64/libc-2.17.so
...
]# cat /proc/self/maps
...
01ec6000-01ee7000 rw-p 00000000 00:00 0 [heap]
7fe2d6cd5000-7fe2dd1ff000 r--p 00000000 fd:00 67111375 /usr/lib/locale/locale-archive
7fe2dd1ff000-7fe2dd3c1000 r-xp 00000000 fd:00 201505758 /usr/lib64/libc-2.17.so
7fe2dd3c1000-7fe2dd5c1000 ---p 001c2000 fd:00 201505758 /usr/lib64/libc-2.17.so
7fe2dd5c1000-7fe2dd5c5000 r--p 001c2000 fd:00 201505758 /usr/lib64/libc-2.17.so
7fe2dd5c5000-7fe2dd5c7000 rw-p 001c6000 fd:00 201505758 /usr/lib64/libc-2.17.so
...
今回の記事中は常に無効にしている。
]# sysctl -w kernel.randomize_va_space=0
kernel.randomize_va_space = 0
ELFファイル
ELFファイルにはセクションとセグメントという概念が存在する。

セクションは用途別に細かく分かれており、コンパイル時に作成される。 セクションの詳細は readelf コマンドで確認できる。
]$ cat main.c
#include <stdio.h>
int main(void) {
return 0;
}
]$ gcc -c main.c
]$ readelf --section-headers main.o
11 個のセクションヘッダ、始点オフセット 0x210:
セクションヘッダ:
[番] 名前 タイプ アドレス オフセット
サイズ EntSize フラグ Link 情報 整列
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
000000000000000b 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 0000004b
0000000000000000 0000000000000000 WA 0 0 1
[ 3] .bss NOBITS 0000000000000000 0000004b
0000000000000000 0000000000000000 WA 0 0 1
...
セグメントはメモリ属性ごとにセクションをまとめたもので、リンク時にリンカスクリプトによって作成される。
参考 ld manual 3 Linker Scripts
どのようなリンカスクリプトが使われているかは gcc のオプションで表示できる。 リンカの具体的な処理の流れは次の資料を参考にする。
参考 リンカの役割 自分メモメモ
]$ gcc -Wl,--verbose main.c
...
OUTPUT_FORMAT("elf64-x86-64", "elf64-x86-64",
"elf64-x86-64")
OUTPUT_ARCH(i386:x86-64)
ENTRY(_start)
SEARCH_DIR("=/usr/x86_64-redhat-linux/lib64"); SEARCH_DIR("=/usr/lib64"); SEARCH_DIR("=/usr/local/lib64"); SEARCH_DIR("=/lib64"); SEARCH_DIR("=/usr/x86_64-redhat-linux/lib"); SEARCH_DIR("=/usr/local/lib"); SEARCH_DIR("=/lib"); SEARCH_DIR("=/usr/lib");
SECTIONS
{
/* Read-only sections, merged into text segment: */
PROVIDE (__executable_start = SEGMENT_START("text-segment", 0x400000)); . = SEGMENT_START("text-segment", 0x400000) + SIZEOF_HEADERS;
.interp : { *(.interp) }
.note.gnu.build-id : { *(.note.gnu.build-id) }
.hash : { *(.hash) }
.gnu.hash : { *(.gnu.hash) }
.dynsym : { *(.dynsym) }
.dynstr : { *(.dynstr) }
.gnu.version : { *(.gnu.version) }
.gnu.version_d : { *(.gnu.version_d) }
...
セグメントの詳細も readelf コマンドで表示できる。
]$ readelf --program-headers $(which cat) -W
Elf ファイルタイプは EXEC (実行可能ファイル) です
エントリポイント 0x402624
9 個のプログラムヘッダ、始点オフセット 64
プログラムヘッダ:
タイプ Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000040 0x0000000000400040 0x0000000000400040 0x0001f8 0x0001f8 R E 0x8
INTERP 0x000238 0x0000000000400238 0x0000000000400238 0x00001c 0x00001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x000000 0x0000000000400000 0x0000000000400000 0x00adcc 0x00adcc R E 0x200000
LOAD 0x00bc48 0x000000000060bc48 0x000000000060bc48 0x0006d8 0x001060 RW 0x200000
DYNAMIC 0x00bde8 0x000000000060bde8 0x000000000060bde8 0x0001d0 0x0001d0 RW 0x8
NOTE 0x000254 0x0000000000400254 0x0000000000400254 0x000044 0x000044 R 0x4
GNU_EH_FRAME 0x009a94 0x0000000000409a94 0x0000000000409a94 0x00030c 0x00030c R 0x4
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
GNU_RELRO 0x00bc48 0x000000000060bc48 0x000000000060bc48 0x0003b8 0x0003b8 R 0x1
セグメントマッピングへのセクション:
セグメントセクション...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .plt.got .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .data.rel.ro .dynamic .got .got.plt .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .jcr .data.rel.ro .dynamic .got
カーネルは、プログラムヘッダをもとに、タイプが LOAD のものをメモリ上にマップする((fs/binfmt_elf.c#load_elf_binary)。各タイプの詳細は elf の man に書いてある。
次に示すように、 LOAD のメモリ開始位置と /proc/pid/maps で表示されるメモリ開始位置が微妙に異なるが、これはページサイズ単位でアライメントされるのが影響しているため。(メモリ属性はページ単位で設定するため)
参考 ELFファイルのレイアウトとメモリへの読み込まれ方がわからない
...
プログラムヘッダ:
タイプ Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
...
LOAD 0x000000 0x0000000000400000 0x0000000000400000 0x00adcc 0x00adcc R E 0x200000
LOAD 0x00bc48 0x000000000060bc48 0x000000000060bc48 0x0006d8 0x001060 RW 0x200000
...
セグメントマッピングへのセクション:
セグメントセクション...
...
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .plt.got .text .fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .jcr .data.rel.ro .dynamic .got .got.plt .data .bss
...
00400000-0040b000 r-xp 00000000 fd:00 134924284 /usr/bin/cat
0060b000-0060c000 r--p 0000b000 fd:00 134924284 /usr/bin/cat
0060c000-0060d000 rw-p 0000c000 fd:00 134924284 /usr/bin/cat
また、 LOAD は2こしかないのに /proc/self/maps は3つある。これは、動的セクションを解決したあとに、次のように、 mprotect で読み込み専用にしているため。
]$ strace cat
execve("/usr/bin/cat", ["cat"], [/* 26 vars */]) = 0
brk(NULL) = 0x60d000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ffff7ff9000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=92377, ...}) = 0
mmap(NULL, 92377, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7ffff7fe2000
close(3) = 0
open("/lib64/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\340$\2\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=2151672, ...}) = 0
mmap(NULL, 3981792, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7ffff7a0e000
mprotect(0x7ffff7bd0000, 2097152, PROT_NONE) = 0
mmap(0x7ffff7dd0000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x1c2000) = 0x7ffff7dd0000
mmap(0x7ffff7dd6000, 16864, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7ffff7dd6000
close(3) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ffff7fe1000
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7ffff7fdf000
arch_prctl(ARCH_SET_FS, 0x7ffff7fdf740) = 0
mprotect(0x7ffff7dd0000, 16384, PROT_READ) = 0
<< ここ >>
mprotect(0x60b000, 4096, PROT_READ) = 0
mprotect(0x7ffff7ffc000, 4096, PROT_READ) = 0
munmap(0x7ffff7fe2000, 92377) = 0
brk(NULL) = 0x60d000
brk(0x62e000) = 0x62e000
brk(NULL) = 0x62e000
open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=106075056, ...}) = 0
mmap(NULL, 106075056, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7ffff14e4000
close(3) = 0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 5), ...}) = 0
fstat(0, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 5), ...}) = 0
fadvise64(0, 0, 0, POSIX_FADV_SEQUENTIAL) = 0
mprotect が呼ばれる瞬間のユーザ空間のスタックトレースを表示させると、_dl_relocate_object で mprotect が実行されていることがわかる。再配置が終わったあとに読み込み専用に変更してるんだと思うが、正直よくわからなかった。
]$ cat bt.stp
probe kernel.function("SyS_mprotect") {
if ($start == 0x60b000) {
print_usyms(ubacktrace())
}
}
]$ stap -v bt.stp -d /usr/lib64/ld-2.17.so
Pass 1: parsed user script and 487 library scripts using 258712virt/55744res/3484shr/52764data kb, in 390usr/40sys/556real ms.
Pass 2: analyzed script: 1 probe, 6 functions, 1 embed, 0 globals using 301968virt/100136res/4536shr/96020data kb, in 660usr/190sys/1385real ms.
Pass 3: translated to C into "/tmp/stapNd5l0P/stap_d8a17641c930c41dc2b44fe8ae56c219_3271_src.c" using 301968virt/100500res/4900shr/96020data kb, in 310usr/60sys/381real ms.
Pass 4: compiled C into "stap_d8a17641c930c41dc2b44fe8ae56c219_3271.ko" in 5270usr/690sys/6181real ms.
Pass 5: starting run.
0x7ffff7df4797 : mprotect+0x7/0x20 [/usr/lib64/ld-2.17.so]
0x7ffff7de700f : _dl_relocate_object+0x98f/0x14e0 [/usr/lib64/ld-2.17.so]
0x7ffff7ddf96a : dl_main+0x2a8a/0x3050 [/usr/lib64/ld-2.17.so]
0x7ffff7df2f2e : _dl_sysdep_start+0x1be/0x2c0 [/usr/lib64/ld-2.17.so]
0x7ffff7ddcbb1 : _dl_start+0x381/0x490 [/usr/lib64/ld-2.17.so]
0x7ffff7ddc128 : check_one_fd.part.0+0x81/0xc9 [/usr/lib64/ld-2.17.so]
^CPass 5: run completed in 10usr/130sys/6057real ms.
ヒープ
実行時にならないとメモリサイズが決まらない事はよくある。そういうときのために、動的にメモリを確保する領域。動的にメモリの利用量が変わるため、 sbrk/brk システムコールを利用してヒープ領域を伸縮する。
例えば malloc はヒープ領域をメインで利用する。mallocの詳細は次のリンクが詳しい。
参考 Glibc malloc internal
参考 malloc(3)のメモリ管理構造
malloc の実装は時代とともに変化していくが、実現したいことは、ヒープ領域を一元管理することでカーネルへのメモリ確保依頼コストを下げる、ということだと思う。
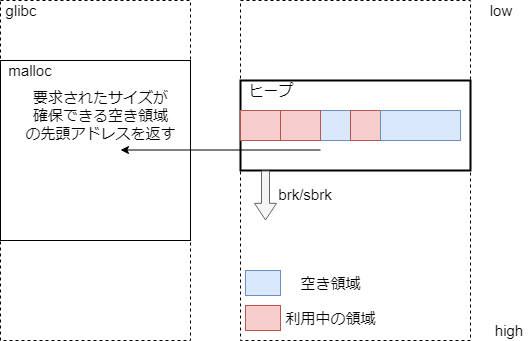
ライブラリ
起動時に動的リンクされる領域。動的リンクされるライブラリは ldd で参照できる。
]$ ldd $(which cat)
linux-vdso.so.1 => (0x00007ffff7ffa000)
libc.so.6 => /lib64/libc.so.6 (0x00007ffff7a0e000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffff7ddb000)
ローダが上記の情報をもとに、 mmap システムコールでライブラリをメモリにマップする。
ローダについては以前調べたので、詳細は割愛する。
C言語がコンパイル~実行されるまで - SIerだけど技術やりたいブログwww.kimullaa.com
スタック
スタック(LIFO)を実現するための領域。関数やローカル変数をスタックに積んでいくことで、関数呼び出しを実現できる。関数を呼び出す側と呼び出される側に呼出規約がある。
ポップしたときもスタック位置を切り替えるだけなので(メモリの解放処理がないので)、高速に処理できる。

また、スタックのメモリ確保上限は ulimit で確認できる。このスタック上限を超えた場合をスタックオーバーフローと呼ぶ。
]$ ulimit -s
8192
勘違いしやすい注意点として、このスタック領域が言語仕様で規定されているスタック領域とイコールではないこと。例えば Java の場合、 JVM プロセス自体が動作するためにスタック領域を利用するが、Java 言語仕様としてのスタック領域はヒープに実装される。JVM 上に OSとCPUの再実装みたいなことをしていて、まさに仮想マシンという感じでカッコイイですね!
参考 メモリとスタックとヒープとプログラミング言語
vsyscall, vdso (virtual dynamic shared object)
0000000000000000 - 00007ffffffffff までがユーザ空間(先頭から [stack] まで)だが、vsyscall はそれ以降の領域(ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall])にある。これは何なのか。
vsyscall は、一部のシステムコール(gettimeofday といった、だれでも実行してよさそうなシステムコール)を カーネルモードに切り替えずに実行することで高速化する仕組み。そのために、カーネル空間のページが、読み込み専用でマップされている。 ただし、現在では、セキュリティ上の理由(ABIのせいでメモリの配置位置を可変にできない)から、読み込み専用でマップされたページにはカーネル空間にスイッチしてエミュレートする処理が記述されているらしい。つまり、高速化のための仕組みだったが高速化されてない。互換性のために残ってるだけみたい。
参考 On vsyscalls and the vDSO
より新しい仕組みとして vdso がある。vdso はユーザ空間へのメモリをマップする位置を可変にできるため、セキュリティも担保できるし、高速に実行できる。
参考 Stack Overflow What are vdso and vsyscall?
参考 Linuxシステムコール徹底ガイド
https://manybutfinite.com/post/anatomy-of-a-program-in-memory/ http://www.coins.tsukuba.ac.jp/~yas/coins/os2-2010/2011-01-25/
コピーオンライト(CoW)
fork した直後は親のメモリと子のメモリは同じ値になるため、fork 時にメモリを親から子へコピーするのは無駄が多い。そのため、親子間で同じ内容のページはできるだけ共有しておき、実メモリの確保を遅らせよう、という仕組み。共有するページは読み込み専用にしておき、親子どちらかがメモリを書き換えたときに親子で別のメモリを確保する。
次のサイトを参考に、コピーオンライトの動きを確認する。
参考 Linux のプロセスが Copy on Write で共有しているメモリのサイズを調べる
次のソースコードを用意する。
- 親でデータを100MB確保する
- fork する
- 30s待ったあとに、子でデータを100MB上書きする
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
enum {
BUFSIZE = 1024 * 1000 * 100, // 100MB
};
char buf[BUFSIZE];
int main (void)
{
int i;
for (i = 0; i < BUFSIZE; i++)
buf[i] = 'a';
pid_t pid = fork();
if (pid == 0) {
sleep(30);
for (i = 0; i < BUFSIZE; i++)
buf[i] = 'b';
while (1) sleep(100);
}
fprintf(stderr, "parent: %d, child: %d\n", getpid(), (int)pid);
wait(NULL);
return 0;
}
実行直後は Shared(CoWに限らないが共有されているページ) が100MBぶん確保されている。
]$ gcc main.c
]$ ./a.out
parent: 109666, child: 109719
]$ cat /proc/109666/smaps | grep heap -A 8
00602000-067aa000 rw-p 00000000 00:00 0 [heap]
Size: 100000 kB
Rss: 100000 kB
Pss: 50000 kB
Shared_Clean: 0 kB
Shared_Dirty: 100000 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Referenced: 100000 kB
]$ cat /proc/109719/smaps | grep heap -A 8
00602000-067aa000 rw-p 00000000 00:00 0 [heap]
Size: 100000 kB
Rss: 100000 kB
Pss: 50000 kB
Shared_Clean: 0 kB
Shared_Dirty: 100000 kB
Private_Clean: 0 kB
Private_Dirty: 0 kB
Referenced: 0 kB
子側でデータが上書きされるのを待ってから再度確認すると、Shared が Private に変更されている。(親子でそれぞれ別の実メモリが確保された)
]$ cat /proc/109666/smaps | grep heap -A 8
00602000-067aa000 rw-p 00000000 00:00 0 [heap]
Size: 100000 kB
Rss: 100000 kB
Pss: 100000 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 100000 kB
Referenced: 100000 kB
]$ cat /proc/109719/smaps | grep heap -A 8
00602000-067aa000 rw-p 00000000 00:00 0 [heap]
Size: 100000 kB
Rss: 100000 kB
Pss: 100000 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 100000 kB
Referenced: 100000 kB
KSM
共有可能なページを見つけて、コピーオンライトに置き換える仕組み。kvmゲストが複数存在する環境だと、ゲスト側のOS部分などの共有可能なページが多く存在する。サーバをkvmホストとして動作させる場合、メモリを有効活用するためにKSMが有効化されることが多い。詳細は次を参考にする。
参考 8.3. KSM (KERNEL SAME-PAGE MERGING)
参考
以下の書籍やサイトを参考にした。